mongoDB實現分頁的方法
時間:2024-03-04 00:33作者:下載吧人氣:28
mongoDB的分頁查詢是通過limit(),skip(),sort()這三個函數組合進行分頁查詢的。
下面這個是我的測試數據
db.test.find().sort({“age”:1});

第一種方法
查詢第一頁的數據:db.test.find().sort({“age”:1}).limit(2);

查詢第二頁的數據:db.test.find().sort({“age”:1}).skip(2).limit(2);

查詢其他頁數以此類推。。。
第二種方法
查詢第一頁的數據:db.test.find().sort({“age”:1}).limit(2);
跟上面的第一種方法一樣的。
查詢第二頁的數據:
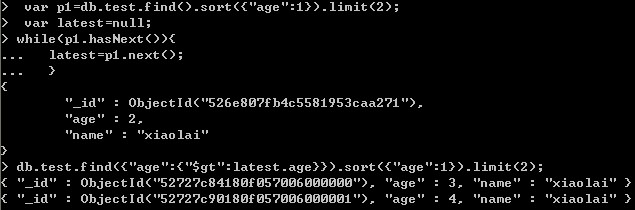
這個是獲取第一頁最后一條記錄的值,然后排除前面的記錄,就能獲取到新的記錄了
總結來說,如果數據量不是很大的話,可以使用第一種方法,畢竟比較簡單,如果數據量比較大的話,使用第二種方法比較好,因為這樣就可以不用到skip()這個函數,skip跳過太多的記錄,效率有點低
經過認真的考慮,第二種方法確實不適合跳頁,而且效率也不是很高
對于海量數據的話,我們要做些特殊的處理,
有以下2種方法
第一種方法

限制分頁的頁數,類似百度的百度的分頁處理,只是顯示前面的七百多條記錄,這樣的就不用考慮性能的問題了,畢竟一般人都只是翻到前面十頁,就找到自己需要的了
后面的統計結果應該是估算出來的,根據查出來的這些記錄所占的比例估算出總的記錄數
第二種方法
我們可以這樣做,假設是根據id排序的,我們可以id跟id所在的頁數的序號存到redis/MemberCached中,
就像這樣,假設每一頁有10條記錄
id page
1 1
2 1
。。。
10 1
11 2
12 2
。。。。
20 2
這樣我們查第一頁的時候就能直接取出十條數據
假設有1億條數據,一條記錄id占4個字節,其他信息的占一個字節,一條記錄就占5個字節
1 0000 0000 *5/(1024*1024)=476MB
這種做法使用空間換時間,一般數據庫查詢的時間大多花在跟數據庫的連接上,放在緩存中,可以大大加快查詢的速度
本篇文章到此結束,如果您有相關技術方面疑問可以聯系我們技術人員遠程解決,感謝大家支持本站!
相關推薦
相關下載
熱門閱覽
- 1如何查看Mongodb的版本號(mongodb版本查看)
- 2從0到1實現mongodb增量更新操作(mongodbinc)
- 3MongoDB為數據安全開啟權限認證(mongodb 權限認證)
- 4數據恢復災難:MongoDB 誤刪數據的解決方案(mongodb誤刪)
- 5如何優雅地關閉MongoDB數據庫(mongodb關閉)
- 6Mongodb解決中文亂碼問題的方法詳解(mongodb中文亂碼)
- 7ongodb架構MongoDB架構:可擴展且高可用的數據庫解決方案(mongodbm)
- 8優化MongoDB的寫入性能(mongodb寫入優化)
- 9如何調用MongoDB數據庫?(調用mongodb)
- 10結構使用MongoDB查看表結構(mongodb查看表)
- 11點備份MongoDB設置定時點備份技巧(mongodb設置時間)
- 12MongoDB:精確定義字段類型的指南(mongodb字段類型)
最新排行
- 1Unlocking the power of MongoDB: Managing 100 databases made easy.(mongodb100)
- 2MongoDB數據類型修改方法(mongodb修改類型)
- 3MongoDB大數據處理權威指南(mongodb大數據處理權威指南)
- 4shardingMongoDB自動分片技術:實現高效穩定的數據訪問(mongodbauto)
- 5如何在MongoDB中添加新用戶?(mongodb加用戶)
- 6Mongodb異步: 改善數據讀寫效率的有效方法(mongodb異步)
- 7提高數據管理效率,選擇MongoDB中國(mongodb中國)
- 8MongoDB在數據庫領域的占有率如何?(mongodb用的多嗎)
- 9使用MongoDB通配符進行精確查詢(mongodb通配符)
- 10使用MongoDB和JSP構建高效的Web應用(mongodbjsp)
- 11MongoDB連接配置:輕松入門!(mongodb 連接配置)
- 12從0到1實現mongodb增量更新操作(mongodbinc)

網友評論