SQL開發(fā)知識(shí):SQL Server索引的原理深入解析
時(shí)間:2024-02-28 13:28作者:下載吧人氣:26
1.聚集索引和非聚集索引
2.索引的結(jié)構(gòu)
3.索引包含列和書簽查找
前言
此文是我之前的筆記整理而來,以索引為入口進(jìn)行探討相關(guān)數(shù)據(jù)庫知識(shí)(又做了修改以讓人更好消化)。SQL Server接觸不久的朋友可以只看以下藍(lán)色字體字,簡單有用節(jié)省時(shí)間;如果是數(shù)據(jù)庫基礎(chǔ)不錯(cuò)的朋友,可以全看,歡迎探討。
索引的概念
索引的用途:我們對(duì)數(shù)據(jù)查詢及處理速度已成為衡量應(yīng)用系統(tǒng)成敗的標(biāo)準(zhǔn),而采用索引來加快數(shù)據(jù)處理速度通常是最普遍采用的優(yōu)化方法。
索引是什么:數(shù)據(jù)庫中的索引類似于一本書的目錄,在一本書中使用目錄可以快速找到你想要的信息,而不需要讀完全書。在數(shù)據(jù)庫中,數(shù)據(jù)庫程序使用索引可以重啊到表中的數(shù)據(jù),而不必掃描整個(gè)表。書中的目錄是一個(gè)字詞以及各字詞所在的頁碼列表,數(shù)據(jù)庫中的索引是表中的值以及各值存儲(chǔ)位置的列表。
索引的利弊:查詢執(zhí)行的大部分開銷是I/O,使用索引提高性能的一個(gè)主要目標(biāo)是避免全表掃描,因?yàn)槿頀呙栊枰獜拇疟P上讀取表的每一個(gè)數(shù)據(jù)頁,如果有索引指向數(shù)據(jù)值,則查詢只需要讀少數(shù)次的磁盤就行啦。所以合理的使用索引能加速數(shù)據(jù)的查詢。但是索引并不總是提高系統(tǒng)的性能,帶索引的表需要在數(shù)據(jù)庫中占用更多的存儲(chǔ)空間,同樣用來增刪數(shù)據(jù)的命令運(yùn)行時(shí)間以及維護(hù)索引所需的處理時(shí)間會(huì)更長。所以我們要合理使用索引,及時(shí)更新去除次優(yōu)索引。
1.聚集索引和非聚集索引
索引分為聚集索引和非聚集索引
1.1 聚集索引
表的數(shù)據(jù)是存儲(chǔ)在數(shù)據(jù)頁中(數(shù)據(jù)頁的PageType標(biāo)記為1),SqlServer一頁是8k,存滿一頁就開辟下一頁存儲(chǔ)。如果表有聚集索引,那么一筆一筆物理數(shù)據(jù)就是按聚集索引字段的大小升/降排序存儲(chǔ)在頁中。當(dāng)對(duì)聚集索引字段更新或中間插入/刪除數(shù)據(jù)時(shí),都會(huì)導(dǎo)致表數(shù)據(jù)移動(dòng)(造成性能一定影響),因?yàn)樗3稚?降排序。
注意,主鍵只是默認(rèn)是聚集索引,它也可以設(shè)置為非聚集索引,也可以在非主鍵字段上設(shè)置為聚集索引,全表只能有一個(gè)聚集索引。
一個(gè)優(yōu)秀的聚集索引字段一般包含以下4個(gè)特性:
(A).自增長
總是在末尾增加記錄,減少分頁和索引碎片。
(B).不被更改
減少數(shù)據(jù)移動(dòng)。
(C).唯一性
唯一性是任何索引最理想的特性,可以明確索引鍵值在排序中的位置。
更重要的是,索引鍵指唯一的話,它在每條記錄里才可以正確指向源數(shù)據(jù)行RID。如果聚集索引鍵值不唯一,SqlServer就需要內(nèi)部生成uniquifier 列組合當(dāng)作聚集鍵保證“鍵值”唯一性;如果非聚集索引鍵值不唯一,就會(huì)增加RID列(聚集索引鍵或者堆表中的行指針)保證“鍵值”唯一性。
思考(可略過):索引“鍵值”在非葉子節(jié)點(diǎn)也有保證唯一性,原因應(yīng)該是為了明確索引記錄在非葉子節(jié)點(diǎn)中的位置。比如有個(gè)非聚集索引字段Name2,表中有很多Name2=’a’的記錄,導(dǎo)致Name2=’a’在非葉子節(jié)點(diǎn)上有多條索引記錄(節(jié)點(diǎn)),這時(shí)候再insert一筆Name2=‘a(chǎn)’的記錄時(shí),就可以根據(jù)非葉子節(jié)點(diǎn)的RID和新增記錄的RID很快確定要insert到哪個(gè)索引記錄(節(jié)點(diǎn))上,如果沒有非葉子節(jié)點(diǎn)的RID,那得遍歷到所有Name2=’a’的葉子節(jié)點(diǎn)才能確定位置。另外,當(dāng)我們select * from Table1 where Name2<=’a’時(shí),返回的數(shù)據(jù)是按非聚集索引Name2和RID排序的,很好理解返回的數(shù)據(jù)就是按這邊索引存儲(chǔ)的順序排序的。這是這條sql查詢時(shí)有用到Name2索引的結(jié)果,如果數(shù)據(jù)庫查詢計(jì)劃因“臨界點(diǎn)”問題選擇直接表數(shù)據(jù)掃描,那返回的數(shù)據(jù)默認(rèn)就是按表數(shù)據(jù)的順序排序的。
為了“鍵值”唯一性,對(duì)于聚集索引,uniquifier 列只在索引值重復(fù)時(shí)增加。對(duì)于非聚集索引,如果創(chuàng)建索引時(shí)沒定義唯一,RID會(huì)在所有記錄增加,就算索引值是唯一的;如果創(chuàng)建索引時(shí)定義唯一,RID只在葉子層增加,用于查找源數(shù)據(jù)行,即書簽查找操作。
(D).字段長度小
聚集索引鍵長度越小,一頁索引頁就可以容納更多索引記錄,進(jìn)而減少索引B樹結(jié)構(gòu)的深度。例如,一個(gè)百萬記錄的表有一個(gè)int聚集索引,可能只需要3層的B樹結(jié)構(gòu)。如果把聚集索引定義在更寬的列(比如uniqueidentifier列需要16 字節(jié)),那么索引的深度會(huì)增加到4層。任何聚集索引查找需要4個(gè)I/O操作(確切的說是4個(gè)邏輯讀),原先只要3個(gè)I/O操作。
同樣,非聚集索引里會(huì)包含聚集索引鍵值,聚集索引鍵長度越小非聚集索引記錄也就越小,一頁索引頁就可以容納更多索引記錄。
1.2 非聚集索引
也是存儲(chǔ)在頁中(PageType標(biāo)記為2的頁,叫索引頁)。比如表T建立了一個(gè)非聚集索引Index_A,那么表T有100條數(shù)據(jù)的話,那么索引Index_A也就有100條數(shù)據(jù)(準(zhǔn)確的說是100條葉子節(jié)點(diǎn)數(shù)據(jù),索引是B樹結(jié)構(gòu),如果樹的高度大于0,那么就有根節(jié)點(diǎn)頁或中間節(jié)點(diǎn)頁數(shù)據(jù),這時(shí)索引數(shù)據(jù)就超過100條),如果表T還有非聚集索引Index_B,那么Index_B也是至少100條數(shù)據(jù),所以索引建越多開銷越大。
更新索引字段、插入一條數(shù)據(jù)、刪除一條數(shù)據(jù)都會(huì)造成索引的維護(hù)從而造成性能的一定影響。在不同情況下,性能影響是不同的。比如當(dāng)你有一個(gè)聚集索引,插入的數(shù)據(jù)又都是在末尾,這樣幾乎是不會(huì)造成數(shù)據(jù)移動(dòng),影響較小;如果插入的數(shù)據(jù)在中間位置,一般會(huì)導(dǎo)致數(shù)據(jù)移動(dòng),而且可能產(chǎn)生分頁和頁碎片,影響就會(huì)稍大一點(diǎn)(如果插入到的中間頁有足夠的剩余空間容納插入的數(shù)據(jù),而且位置是在頁末,也是不會(huì)造成數(shù)據(jù)移動(dòng))
2.索引的結(jié)構(gòu)
都說SqlServer的索引是B樹結(jié)構(gòu)(這邊假定你對(duì)B樹結(jié)構(gòu)有一定了解),那它到底長什么個(gè)模樣呢,可以用Sql語句來查看它的邏輯呈現(xiàn)。
新建查詢執(zhí)行語法: DBCC IND(Test,OrderBo,-1) –其中Test庫的OrderBo表有1萬筆數(shù)據(jù),有聚集索引Id主鍵字段
(不妨自己動(dòng)手建個(gè)表,有聚集索引字段,插入1萬表數(shù)據(jù),然后執(zhí)行這個(gè)語法看看,會(huì)收獲很多,百聞不如一見)
執(zhí)行結(jié)果:
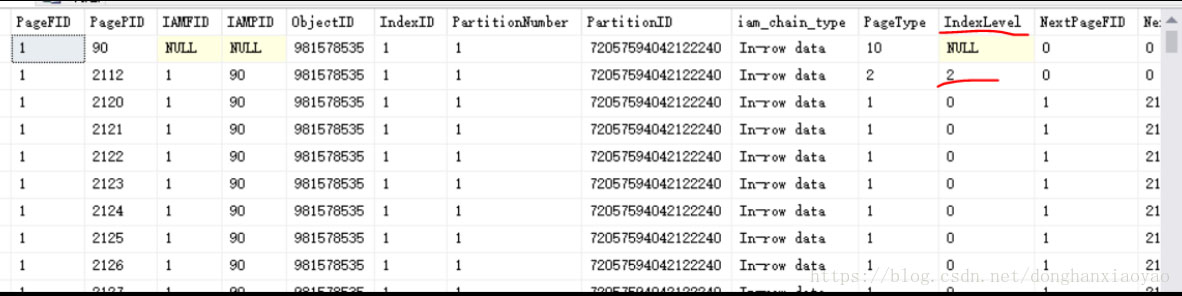
如上圖,看到一個(gè)IndexLevel=2的索引頁2112(這邊它就是B樹的根節(jié)點(diǎn),IndexLevel最大的就是根節(jié)點(diǎn),往下就是子級(jí)、子子級(jí)…只有一個(gè)根頁作為B樹結(jié)構(gòu)的訪問入口點(diǎn)),說明一定還有IndexLevel=1的索引頁和IndexLevel=0的葉子頁。由于這邊是聚集索引,因此當(dāng)IndexLevel=0的葉子頁就是數(shù)據(jù)頁,存儲(chǔ)的是一筆一筆的物理數(shù)據(jù)。如上圖也可以看到,IndexLevel=0的行的PageType等于1,就是代表數(shù)據(jù)頁,上面1.1章節(jié)講到聚集索引時(shí),也有提到PageType=1;而如果是非聚集索引,IndexLevel=0的葉子頁,PageType是等于 2,仍然是索引頁。
同樣,我們用Sql命令DBCC PAGE看一看
— DBCC TRACEON(3604,-1)
DBCC PAGE(Test,1,2112,3)
–根節(jié)點(diǎn)2112,可以查出它的兩個(gè)子節(jié)點(diǎn)2280和2448,然后對(duì)這兩個(gè)子節(jié)點(diǎn)再作DBCC PAGE查詢
DBCC PAGE(Test,1,2280,3)
DBCC PAGE(Test,1,2448,3)
- 3.索引包含列和書簽查找
- 前言
此文是我之前的筆記整理而來,以索引為入口進(jìn)行探討相關(guān)數(shù)據(jù)庫知識(shí)(又做了修改以讓人更好消化)。SQL Server接觸不久的朋友可以只看以下藍(lán)色字體字,簡單有用節(jié)省時(shí)間;如果是數(shù)據(jù)庫基礎(chǔ)不錯(cuò)的朋友,可以全看,歡迎探討。
索引的概念
索引的用途:我們對(duì)數(shù)據(jù)查詢及處理速度已成為衡量應(yīng)用系統(tǒng)成敗的標(biāo)準(zhǔn),而采用索引來加快數(shù)據(jù)處理速度通常是最普遍采用的優(yōu)化方法。
索引是什么:數(shù)據(jù)庫中的索引類似于一本書的目錄,在一本書中使用目錄可以快速找到你想要的信息,而不需要讀完全書。在數(shù)據(jù)庫中,數(shù)據(jù)庫程序使用索引可以重啊到表中的數(shù)據(jù),而不必掃描整個(gè)表。書中的目錄是一個(gè)字詞以及各字詞所在的頁碼列表,數(shù)據(jù)庫中的索引是表中的值以及各值存儲(chǔ)位置的列表。
索引的利弊:查詢執(zhí)行的大部分開銷是I/O,使用索引提高性能的一個(gè)主要目標(biāo)是避免全表掃描,因?yàn)槿頀呙栊枰獜拇疟P上讀取表的每一個(gè)數(shù)據(jù)頁,如果有索引指向數(shù)據(jù)值,則查詢只需要讀少數(shù)次的磁盤就行啦。所以合理的使用索引能加速數(shù)據(jù)的查詢。但是索引并不總是提高系統(tǒng)的性能,帶索引的表需要在數(shù)據(jù)庫中占用更多的存儲(chǔ)空間,同樣用來增刪數(shù)據(jù)的命令運(yùn)行時(shí)間以及維護(hù)索引所需的處理時(shí)間會(huì)更長。所以我們要合理使用索引,及時(shí)更新去除次優(yōu)索引。
1.聚集索引和非聚集索引
索引分為聚集索引和非聚集索引
1.1 聚集索引
表的數(shù)據(jù)是存儲(chǔ)在數(shù)據(jù)頁中(數(shù)據(jù)頁的PageType標(biāo)記為1),SqlServer一頁是8k,存滿一頁就開辟下一頁存儲(chǔ)。如果表有聚集索引,那么一筆一筆物理數(shù)據(jù)就是按聚集索引字段的大小升/降排序存儲(chǔ)在頁中。當(dāng)對(duì)聚集索引字段更新或中間插入/刪除數(shù)據(jù)時(shí),都會(huì)導(dǎo)致表數(shù)據(jù)移動(dòng)(造成性能一定影響),因?yàn)樗3稚?降排序。
注意,主鍵只是默認(rèn)是聚集索引,它也可以設(shè)置為非聚集索引,也可以在非主鍵字段上設(shè)置為聚集索引,全表只能有一個(gè)聚集索引。
一個(gè)優(yōu)秀的聚集索引字段一般包含以下4個(gè)特性:
(A).自增長
總是在末尾增加記錄,減少分頁和索引碎片。
(B).不被更改
減少數(shù)據(jù)移動(dòng)。
(C).唯一性
唯一性是任何索引最理想的特性,可以明確索引鍵值在排序中的位置。
更重要的是,索引鍵指唯一的話,它在每條記錄里才可以正確指向源數(shù)據(jù)行RID。如果聚集索引鍵值不唯一,SqlServer就需要內(nèi)部生成uniquifier 列組合當(dāng)作聚集鍵保證“鍵值”唯一性;如果非聚集索引鍵值不唯一,就會(huì)增加RID列(聚集索引鍵或者堆表中的行指針)保證“鍵值”唯一性。
思考(可略過):索引“鍵值”在非葉子節(jié)點(diǎn)也有保證唯一性,原因應(yīng)該是為了明確索引記錄在非葉子節(jié)點(diǎn)中的位置。比如有個(gè)非聚集索引字段Name2,表中有很多Name2=’a’的記錄,導(dǎo)致Name2=’a’在非葉子節(jié)點(diǎn)上有多條索引記錄(節(jié)點(diǎn)),這時(shí)候再insert一筆Name2=‘a(chǎn)’的記錄時(shí),就可以根據(jù)非葉子節(jié)點(diǎn)的RID和新增記錄的RID很快確定要insert到哪個(gè)索引記錄(節(jié)點(diǎn))上,如果沒有非葉子節(jié)點(diǎn)的RID,那得遍歷到所有Name2=’a’的葉子節(jié)點(diǎn)才能確定位置。另外,當(dāng)我們select * from Table1 where Name2<=’a’時(shí),返回的數(shù)據(jù)是按非聚集索引Name2和RID排序的,很好理解返回的數(shù)據(jù)就是按這邊索引存儲(chǔ)的順序排序的。這是這條sql查詢時(shí)有用到Name2索引的結(jié)果,如果數(shù)據(jù)庫查詢計(jì)劃因“臨界點(diǎn)”問題選擇直接表數(shù)據(jù)掃描,那返回的數(shù)據(jù)默認(rèn)就是按表數(shù)據(jù)的順序排序的。
為了“鍵值”唯一性,對(duì)于聚集索引,uniquifier 列只在索引值重復(fù)時(shí)增加。對(duì)于非聚集索引,如果創(chuàng)建索引時(shí)沒定義唯一,RID會(huì)在所有記錄增加,就算索引值是唯一的;如果創(chuàng)建索引時(shí)定義唯一,RID只在葉子層增加,用于查找源數(shù)據(jù)行,即書簽查找操作。
(D).字段長度小
聚集索引鍵長度越小,一頁索引頁就可以容納更多索引記錄,進(jìn)而減少索引B樹結(jié)構(gòu)的深度。例如,一個(gè)百萬記錄的表有一個(gè)int聚集索引,可能只需要3層的B樹結(jié)構(gòu)。如果把聚集索引定義在更寬的列(比如uniqueidentifier列需要16 字節(jié)),那么索引的深度會(huì)增加到4層。任何聚集索引查找需要4個(gè)I/O操作(確切的說是4個(gè)邏輯讀),原先只要3個(gè)I/O操作。
同樣,非聚集索引里會(huì)包含聚集索引鍵值,聚集索引鍵長度越小非聚集索引記錄也就越小,一頁索引頁就可以容納更多索引記錄。
1.2 非聚集索引
也是存儲(chǔ)在頁中(PageType標(biāo)記為2的頁,叫索引頁)。比如表T建立了一個(gè)非聚集索引Index_A,那么表T有100條數(shù)據(jù)的話,那么索引Index_A也就有100條數(shù)據(jù)(準(zhǔn)確的說是100條葉子節(jié)點(diǎn)數(shù)據(jù),索引是B樹結(jié)構(gòu),如果樹的高度大于0,那么就有根節(jié)點(diǎn)頁或中間節(jié)點(diǎn)頁數(shù)據(jù),這時(shí)索引數(shù)據(jù)就超過100條),如果表T還有非聚集索引Index_B,那么Index_B也是至少100條數(shù)據(jù),所以索引建越多開銷越大。
更新索引字段、插入一條數(shù)據(jù)、刪除一條數(shù)據(jù)都會(huì)造成索引的維護(hù)從而造成性能的一定影響。在不同情況下,性能影響是不同的。比如當(dāng)你有一個(gè)聚集索引,插入的數(shù)據(jù)又都是在末尾,這樣幾乎是不會(huì)造成數(shù)據(jù)移動(dòng),影響較小;如果插入的數(shù)據(jù)在中間位置,一般會(huì)導(dǎo)致數(shù)據(jù)移動(dòng),而且可能產(chǎn)生分頁和頁碎片,影響就會(huì)稍大一點(diǎn)(如果插入到的中間頁有足夠的剩余空間容納插入的數(shù)據(jù),而且位置是在頁末,也是不會(huì)造成數(shù)據(jù)移動(dòng))
2.索引的結(jié)構(gòu)
都說SqlServer的索引是B樹結(jié)構(gòu)(這邊假定你對(duì)B樹結(jié)構(gòu)有一定了解),那它到底長什么個(gè)模樣呢,可以用Sql語句來查看它的邏輯呈現(xiàn)。
新建查詢執(zhí)行語法: DBCC IND(Test,OrderBo,-1) –其中Test庫的OrderBo表有1萬筆數(shù)據(jù),有聚集索引Id主鍵字段
(不妨自己動(dòng)手建個(gè)表,有聚集索引字段,插入1萬表數(shù)據(jù),然后執(zhí)行這個(gè)語法看看,會(huì)收獲很多,百聞不如一見)
執(zhí)行結(jié)果:
如上圖,看到一個(gè)IndexLevel=2的索引頁2112(這邊它就是B樹的根節(jié)點(diǎn),IndexLevel最大的就是根節(jié)點(diǎn),往下就是子級(jí)、子子級(jí)…只有一個(gè)根頁作為B樹結(jié)構(gòu)的訪問入口點(diǎn)),說明一定還有IndexLevel=1的索引頁和IndexLevel=0的葉子頁。由于這邊是聚集索引,因此當(dāng)IndexLevel=0的葉子頁就是數(shù)據(jù)頁,存儲(chǔ)的是一筆一筆的物理數(shù)據(jù)。如上圖也可以看到,IndexLevel=0的行的PageType等于1,就是代表數(shù)據(jù)頁,上面1.1章節(jié)講到聚集索引時(shí),也有提到PageType=1;而如果是非聚集索引,IndexLevel=0的葉子頁,PageType是等于 2,仍然是索引頁。
同樣,我們用Sql命令DBCC PAGE看一看
— DBCC TRACEON(3604,-1)
DBCC PAGE(Test,1,2112,3)
–根節(jié)點(diǎn)2112,可以查出它的兩個(gè)子節(jié)點(diǎn)2280和2448,然后對(duì)這兩個(gè)子節(jié)點(diǎn)再作DBCC PAGE查詢
DBCC PAGE(Test,1,2280,3)
DBCC PAGE(Test,1,2448,3)
相關(guān)推薦
- PostgreSQL數(shù)據(jù)庫中匿名塊的寫法實(shí)例
- 詳解PostgreSql數(shù)據(jù)庫對(duì)象信息及應(yīng)用
- 異常處理:SQL Server Alwayson數(shù)據(jù)庫添加監(jiān)聽器失敗的解決
- SQL開發(fā)知識(shí):SqlServer 表單查詢問題及解決方法
- PostgreSQL數(shù)據(jù)庫事務(wù)實(shí)現(xiàn)方法分析
- Mongodb數(shù)據(jù)庫誤刪后的恢復(fù)方法(兩種)
- Postgresql 數(shù)據(jù)庫 varchar()字符占用多少字節(jié)介紹
- 淺談postgresql數(shù)據(jù)庫varchar、char、text的比較
- MongoDB數(shù)據(jù)庫中索引和explain的使用教程
- mongodb數(shù)據(jù)庫基礎(chǔ)知識(shí)之連表查詢
相關(guān)下載
熱門閱覽
- 1SQL開發(fā)知識(shí):MyBatis SQL xml處理小于號(hào)與大于號(hào)正確的格式
- 2SQL基礎(chǔ):SQLServer2019 數(shù)據(jù)庫的基本使用之圖形化界面操作的實(shí)現(xiàn)
- 3SQL異常:教你sqlserver連接錯(cuò)誤之SQL評(píng)估期已過的問題解決方法
- 4SQL報(bào)錯(cuò):由于系統(tǒng)錯(cuò)誤 126 (SQL Server),指定驅(qū)動(dòng)程序無法加載問題的處理
- 5SQL開發(fā)知識(shí):SQL中Truncate的用法
- 6一文教你SQL Server2012的數(shù)據(jù)庫備份和還原的教程
- 7數(shù)據(jù)庫恢復(fù)之 delete誤刪數(shù)據(jù)使用SCN號(hào)恢復(fù)的詳細(xì)方希
- 8SQL開發(fā)知識(shí):SQL Server執(zhí)行動(dòng)態(tài)SQL的正確方法
- 9SQL基礎(chǔ):SQL?Server的全文搜索功能
- 10SQL開發(fā)知識(shí):SQL Server數(shù)據(jù)庫查找表名或列名中包含空格的表和列
- 11PL/SQL Developer過期的解決方法
- 12Navicat 如何連接SQLServer數(shù)據(jù)庫詳細(xì)步驟截圖
最新排行
- 1SQL開發(fā)知識(shí):SQL注入工具
- 2SQL開發(fā)知識(shí):SQL 在自增列插入指定數(shù)據(jù)的操作方法
- 3Sql Server2012數(shù)據(jù)庫使用IP登錄服務(wù)器的配置教程
- 4SQL開發(fā)知識(shí):Navicat導(dǎo)出.sql文件方法
- 5SQL開發(fā)知識(shí):SQL Server表和索引存儲(chǔ)結(jié)構(gòu)
- 6SQL開發(fā)知識(shí):Sql注入原理簡介
- 7SQL開發(fā)知識(shí):SQL Server Management Studio(SSMS)復(fù)制數(shù)據(jù)庫的方法
- 8SQL開發(fā)知識(shí):SQL Server執(zhí)行動(dòng)態(tài)SQL的正確方法
- 9SQL開發(fā)知識(shí):SQL Server Parameter Sniffing及其改進(jìn)方法
- 10SQL開發(fā)知識(shí):sql server2008調(diào)試存儲(chǔ)過程的步驟
- 11SQL開發(fā)知識(shí):SQL Server非動(dòng)態(tài) SQL語句來對(duì)動(dòng)態(tài)查詢進(jìn)行執(zhí)行
- 12一文帶你詳解SQL Server 2016數(shù)據(jù)庫快照代理過程

網(wǎng)友評(píng)論