MongoDB分片詳解
時間:2024-02-09 10:40作者:下載吧人氣:21
分片是MongoDB的擴展方式,通過分片能夠增加更多的機器來用對不斷增加的負載和數據,還不影響應用.
1.分片簡介
分片是指將數據拆分,將其分散存在不同機器上的過程.有時也叫分區.將數據分散在不同的機器上,不需要功能
強大的大型計算機就可以存儲更多的數據,處理更大的負載.
使用幾乎所有數據庫軟件都能進行手動分片,應用需要維護與若干不同數據庫服務器的連接,每個連接還是完全
獨立的.應用程序管理不同服務器上的不同數據,存儲查村都需要在正確的服務器上進行.這種方法可以很好的工作,但是也
難以維護,比如向集群添加節點或從集群刪除節點都很困難,調整數據分布和負載模式也不輕松.
MongoDB支持自動分片,可以擺脫手動分片的管理.集群自動切分數據,做負載均衡.
2.MongoDB的自動分片
MongoDB分片的基本思想就是將集合切分成小塊.這些塊分散到若干片里面,每個片只負責總數據的一部分.應用程序不必知道
哪片對應哪些數據,甚至不需要知道數據已經被拆分了,所以在分片之前要運行一個路由進程,進程名mongos,這個路由器知道
所有數據的存放位置,所以應用可以連接它來正常發送請求.對應用來說,它僅知道連接了一個普通的mongod.路由器知道和片的
對應關系,能夠轉發請求到正確的片上.如果請求有了回應,路由器將其收集起來回送給應用.
在沒有分片的時候,客戶端連接mongod進程,分片時客戶端會連接mongos進程.mongos對應用隱藏了分片的細節.
從應用的角度看,分片和不分片沒有區別.所以需要擴展的時候,不必修改應用程序的代碼.
不分片的客戶端連接:
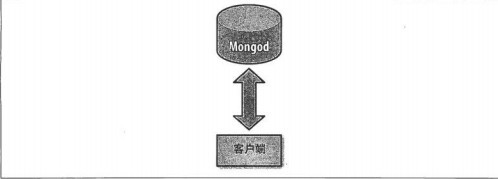
分片的客戶端連接:
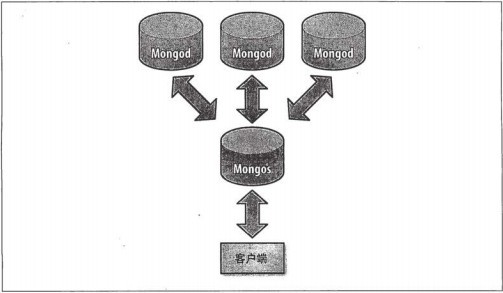
什么時候需要分片:
a.機器的磁盤不夠用了
b.單個mongod已經不能滿足些數據的性能需要了
c.想將大量數據放在內存中提高性能
一般來說,先要從不分片開始,然后在需要的時候將其轉換成分片.
3.片鍵
設置分片時,需要從集合里面選一個鍵,用該鍵的值作為數據拆分的依據.這個鍵成為片鍵.
假設有個文檔集合表示的是人員,如果選擇名字”name”做為片鍵,第一篇可能會存放名字以A-F開頭的文檔.
第二片存G-P開頭的文檔,第三篇存Q-Z的文檔.隨著增加或刪除片,MongoDB會重新平衡數據,是每片的流量比較
均衡,數據量也在合理范圍內(如流量較大的片存放的數據或許會比流量下的片數據要少些)
4.將已有的集合分片
假設有個存儲日志的集合,現在要分片.我們開啟分片功能,然后告訴MongoDB用”timestamp”作為片鍵,就要所有數據放到
了一個片上.可以隨意插入數據,但總會是在一個片上.
然后,新增一個片.這個片建好并運行了以后,MongoDB就會把集合拆分成兩半,成為塊.每個塊中包含片鍵值在一定
范圍內的所有文檔,假設其中一塊包含時間戳在2011.11.11前的文檔,則另一塊含有2011.11.11以后的文檔.其中
一塊會被移動到新片上.如果新文檔的時間戳在2011.11.11之前,則添加到第一塊,否則添加到第二塊.
5.遞增片鍵還是隨機片鍵
片鍵的選擇決定了插入操作在片之間的分布.
如果選擇了像”timestamp”這樣的鍵,這個值可能不斷增長,而且沒有太大的間斷,就會將所有數據發送到一個片上
(含有2011.11.11以后日期的那片).如果有添加了新片,再拆分數據,還是會都導入到一臺服務器上.添加了新片,
MongoDB肯能會將2011.11.11以后的拆分成2011.11.11-2021.11.11.如果文檔的時間大于2021.11.11以后,
所有的文檔還會以最后一片插入.這就不適合寫入負載很高情況,但按照片鍵查詢會非常高效.
如果寫入負載比較高,想均勻分散負載到各個片,就得選擇分布均勻的片鍵.日志例子中時間戳的散列值,沒有模式的”logMessage”
都是復合這個條件的.
不論片鍵隨機跳躍還是穩定增加,片鍵的變化很重要.如,如果有個”logLevel”鍵的值只有3種值”DEBUG”,”WARN”,”ERROR”,
MongoDB無論如何也不能把它作為片鍵將數據分成多于3片(因為只有3個值).如果鍵的變化太少,但又想讓其作為片鍵,
可以把這個鍵與一個變化較大的鍵組合起來,創建一個復合片鍵,如”logLevel”和”timestamp”組合.
選擇片鍵并創建片鍵很像索引,以為二者原理相似.事實上,片鍵也是最常用的索引.
6.片鍵對操作的影響
最終用戶應該無法區分是否分片,但是要了解選擇不同片鍵情況下的查詢有何不同.
假設還是那個表示人員的集合,按照”name”分片,有3個片,其名字首字母的范圍是A-Z.下面以不同的方式查詢:
db.people.find({"name":"Refactor"})
相關推薦
- 詳解MongoDB數據庫基礎操作及實例
- Centos 7.2中MongoDB數據庫的安裝與卸載教程
- 阿里云CentOS7安裝Mongodb教程
- MongoDB安全配置詳解
- MongoDB系列教程(四):設置用戶訪問權限
- mongodb錯誤tcmalloc: large alloc out of memory, printing stack and exiting解決辦法
- windows與mac安裝mongodb數據庫的方法步驟與注意事項
- MongoDB搭建高可用集群的完整步驟(3個分片+3個副本)
- PostgreSQL教程(五):函數和操作符詳解(1)
- MongoDB固定集合(capped collection)的知識小結
相關下載
熱門閱覽
- 1如何查看Mongodb的版本號(mongodb版本查看)
- 2從0到1實現mongodb增量更新操作(mongodbinc)
- 3MongoDB為數據安全開啟權限認證(mongodb 權限認證)
- 4數據恢復災難:MongoDB 誤刪數據的解決方案(mongodb誤刪)
- 5如何優雅地關閉MongoDB數據庫(mongodb關閉)
- 6Mongodb解決中文亂碼問題的方法詳解(mongodb中文亂碼)
- 7優化MongoDB的寫入性能(mongodb寫入優化)
- 8ongodb架構MongoDB架構:可擴展且高可用的數據庫解決方案(mongodbm)
- 9如何調用MongoDB數據庫?(調用mongodb)
- 10結構使用MongoDB查看表結構(mongodb查看表)
- 11點備份MongoDB設置定時點備份技巧(mongodb設置時間)
- 12MongoDB:精確定義字段類型的指南(mongodb字段類型)
最新排行
- 1Unlocking the power of MongoDB: Managing 100 databases made easy.(mongodb100)
- 2MongoDB數據類型修改方法(mongodb修改類型)
- 3MongoDB大數據處理權威指南(mongodb大數據處理權威指南)
- 4shardingMongoDB自動分片技術:實現高效穩定的數據訪問(mongodbauto)
- 5如何在MongoDB中添加新用戶?(mongodb加用戶)
- 6Mongodb異步: 改善數據讀寫效率的有效方法(mongodb異步)
- 7提高數據管理效率,選擇MongoDB中國(mongodb中國)
- 8MongoDB在數據庫領域的占有率如何?(mongodb用的多嗎)
- 9使用MongoDB通配符進行精確查詢(mongodb通配符)
- 10使用MongoDB和JSP構建高效的Web應用(mongodbjsp)
- 11MongoDB連接配置:輕松入門!(mongodb 連接配置)
- 12從0到1實現mongodb增量更新操作(mongodbinc)

網友評論