詳解分布式文檔存儲數據庫 MongoDB分片集群的問題
時間:2024-02-08 11:17作者:下載吧人氣:39
前文我們聊到了mongodb的副本集以及配置副本集,回顧請參考 今天我們來聊下mongodb的分片;
1、什么是分片?為什么要分片?
我們知道數據庫服務器一般出現瓶頸是在磁盤io上,或者高并發網絡io,又或者單臺server的cpu、內存等等一系列原因;于是,為了解決這些瓶頸問題,我們就必須擴展服務器性能;通常擴展服務器有向上擴展和向外擴展;所謂向上擴展就是給服務器加更大的磁盤,使用更大更好的內存,更換更好的cpu;這種擴展在一定程度上是可以解決性能瓶頸問題,但隨著數據量大增大,瓶頸會再次出現;所以通常這種向上擴展的方式不推薦;向外擴展是指一臺服務器不夠加兩臺,兩臺不夠加三臺,以這種方式擴展,只要出現瓶頸我們就可以使用增加服務器來解決;這樣一來服務器性能解決了,但用戶的讀寫怎么分散到多個服務器上去呢?所以我們還要想辦法把數據切分成多塊,讓每個服務器只保存整個數據集的部分數據,這樣一來使得原來一個很大的數據集就通過切片的方式,把它切分成多分,分散的存放在多個服務器上,這就是分片;分片是可以有效解決用戶寫操作性能瓶頸;雖然解決了服務器性能問題和用戶寫性能問題,同時也帶來了一個新問題,就是用戶的查詢;我們把整個數據集分散到多個server上,那么用戶怎么查詢數據呢?比如用戶要查詢年齡大于30的用戶,該怎么查詢呢?而年齡大于30的用戶的數據,可能server1上有一部分數據,server2上有部分數據,我們怎么才能夠把所有滿足條件的數據全部查詢到呢?這個場景有點類似我們之前說的mogilefs的架構,用戶上傳圖片到mogilefs首先要把圖片的元數據寫進tracker,然后在把數據存放在對應的data節點,這樣一來用戶來查詢,首先找tracker節點,tracker會把用戶的請求文件的元數據告訴客戶端,然后客戶端在到對應的data節點取數據,最后拼湊成一張圖片;而在mongodb上也是很類似,不同的的是在mogilefs上,客戶端需要自己去和后端的data節點交互,取出數據;在mongdb上客戶端不需要直接和后端的data節點交互,而是通過mongodb專有的客戶端代理去代客戶端交互,最后把數據統一由代理返回給客戶端;這樣一來就可以解決用戶的查詢問題;簡單講所謂分片就是把一個大的數據集通過切分的方式切分成多分,分散的存放在多個服務器上;分片的目的是為了解決數據量過大而導致的性能問題;
2、數據集分片示意圖
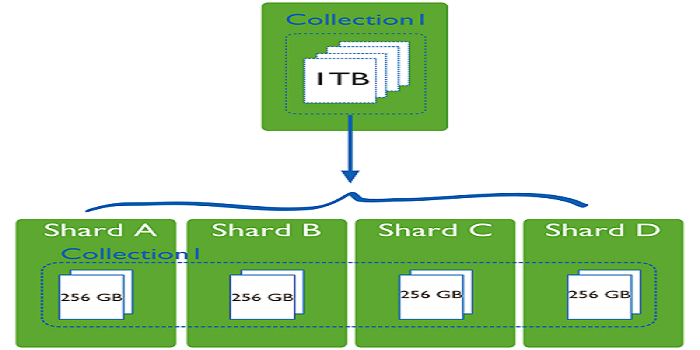
提示:我們通過分片,可以將原本1T的數據集,平均分成4分,每個節點存儲原有數據集的1/4,使得原來用一臺服務器處理1T的數據,現在可以用4臺服務器來處理,這樣一來就有效的提高了數據處理過程;這也是分布式系統的意義;在mongodb中我們把這種共同處理一個數據集的部分數據的節點叫shard,我們把使用這種分片機制的mongodb集群就叫做mongodb分片集群;
3、mongodb分片集群架構
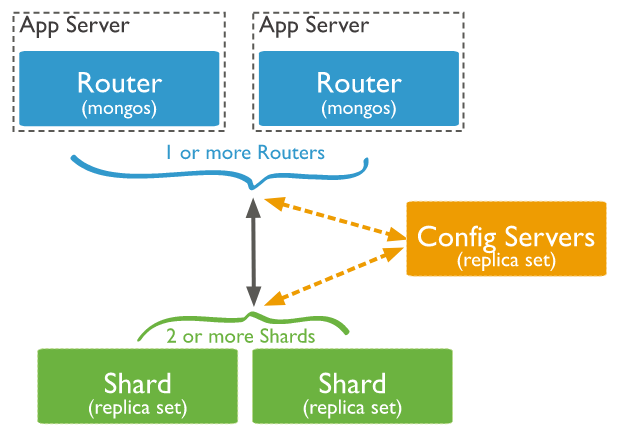
提示:在mongodb分片集群中,通常有三類角色,第一類是router角色,router角色主要用來接收客戶端的讀寫請求,主要運行mongos這個服務;為了使得router角色的高可用,通常會用多個節點來組成router高可用集群;第二類是config server,這類角色主要用來保存mongodb分片集群中的數據和集群的元數據信息,有點類似mogilefs中的tracker的作用;為了保證config server的高可用性,通常config server也會將其運行為一個副本集;第三類是shard角色,這類角色主要用來存放數據,類似mogilefs的數據節點,為了保證數據的高可用和完整性,通常每個shard是一個副本集;
4、mongodb分片集群工作過程
首先用戶將請求發送給router,router接收到用戶請求,然后去找config server拿對應請求的元數據信息,router拿到元數據信息后,然后再向對應的shard請求數據,最后將數據整合后響應給用戶;在這個過程中router 就相當于mongodb的一個客戶端代理;而config server用來存放數據的元數據信息,這些信息主要包含了那些shard上存放了那些數據,對應的那些數據存放在那些shard上,和mogilefs上的tracker非常類似,主要存放了兩張表,一個是以數據為中心的一張表,一個是以shard節點為中心的一張表;
5、mongodb是怎么分片的?
在mongodb的分片集群中,分片是按照collection字段來分的,我們把指定的字段叫shard key;根據shard key的取值不同和應用場景,我們可以基于shard key取值范圍來分片,也可以基于shard key做hash分片;分好片以后將結果保存在config server上;在configserver 上保存了每一個分片對應的數據集;比如我們基于shardkey的范圍來分片,在configserver上就記錄了一個連續范圍的shardkey的值都保存在一個分片上;如下圖
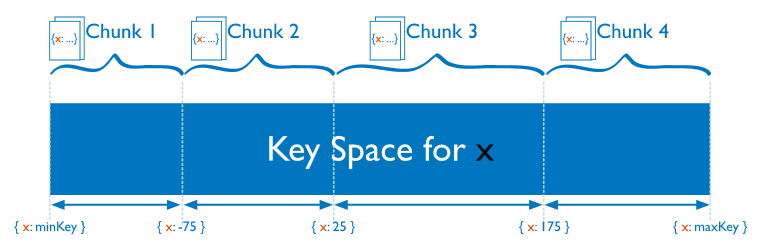
上圖主要描述了基于范圍的分片,從shardkey最小值到最大值進行分片,把最小值到-75這個范圍值的數據塊保存在第一個分片上,把-75到25這個范圍值的數據塊保存在第二個分片上,依次類推;這種基于范圍的分片,很容易導致某個分片上的數據過大,而有的分片上的數據又很小,造成分片數據不均勻;所以除了基與shard key的值的范圍分片,也可以基于shard key的值做hash分片,如下圖
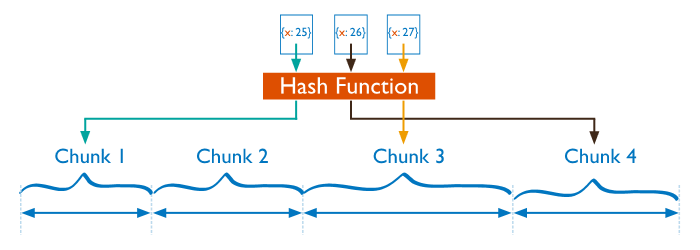
基于hash分片,主要是對shardkey做hash計算后,然后根據最后的結果落在哪個分片上就把對應的數據塊保存在對應的分片上;比如我們把shandkey做hash計算,然后對分片數量進行取模計算,如果得到的結果是0,那么就把對應的數據塊保存在第一個分片上,如果取得到結果是1就保存在第二個分片上依次類推;這種基于hash分片,就有效的降低分片數據不均衡的情況,因為hash計算的值是散列的;
除了上述兩種切片的方式以外,我們還可以根據區域切片,也叫基于列表切片,如下圖
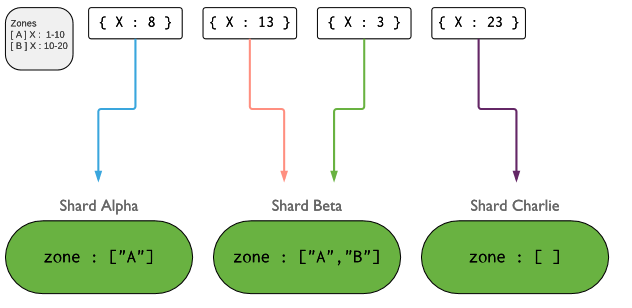
上圖主要描述了基于區域分片,這種分片一般是針對shardkey的取值范圍不是一個順序的集合,而是一個離散的集合,比如我們可用這種方式對全國省份這個字段做切片,把流量特別大的省份單獨切一個片,把流量小的幾個省份組合切分一片,把國外的訪問或不是國內省份的切分為一片;這種切片有點類似給shardkey做分類;不管用什么方式去做分片,我們盡可能的遵循寫操作要越分散越好,讀操作要越集中越好;
6、mongodb分片集群搭建
環境說明
| 主機名 | 角色 | ip地址 |
| node01 | router | 192.168.0.41 |
| node02/node03/node04 | config server replication set |
192.168.0.42 192.168.0.43 192.168.0.44 |
| node05/node06/node07 | shard1 replication set |
192.168.0.45 192.168.0.46 192.168.0.47 |
| node08/node09/node10 | shard2 replication set |
192.168.0.48 192.168.0.49 192.168.0.50 |
基礎環境,各server做時間同步,關閉防火墻,關閉selinux,ssh互信,主機名解析
主機名解析
[root@node01 ~]# cat /etc/hosts
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
192.168.0.99 time.test.org time-node
192.168.0.41 node01.test.org node01
192.168.0.42 node02.test.org node02
192.168.0.43 node03.test.org node03
192.168.0.44 node04.test.org node04
192.168.0.45 node05.test.org node05
192.168.0.46 node06.test.org node06
192.168.0.47 node07.test.org node07
192.168.0.48 node08.test.org node08
192.168.0.49 node09.test.org node09
192.168.0.50 node10.test.org node10
192.168.0.51 node11.test.org node11
192.168.0.52 node12.test.org node12
[root@node01 ~]#
相關推薦
相關下載
熱門閱覽
- 1如何查看Mongodb的版本號(mongodb版本查看)
- 2從0到1實現mongodb增量更新操作(mongodbinc)
- 3MongoDB為數據安全開啟權限認證(mongodb 權限認證)
- 4數據恢復災難:MongoDB 誤刪數據的解決方案(mongodb誤刪)
- 5如何優雅地關閉MongoDB數據庫(mongodb關閉)
- 6Mongodb解決中文亂碼問題的方法詳解(mongodb中文亂碼)
- 7ongodb架構MongoDB架構:可擴展且高可用的數據庫解決方案(mongodbm)
- 8優化MongoDB的寫入性能(mongodb寫入優化)
- 9如何調用MongoDB數據庫?(調用mongodb)
- 10結構使用MongoDB查看表結構(mongodb查看表)
- 11點備份MongoDB設置定時點備份技巧(mongodb設置時間)
- 12MongoDB:精確定義字段類型的指南(mongodb字段類型)
最新排行
- 1Unlocking the power of MongoDB: Managing 100 databases made easy.(mongodb100)
- 2MongoDB數據類型修改方法(mongodb修改類型)
- 3MongoDB大數據處理權威指南(mongodb大數據處理權威指南)
- 4shardingMongoDB自動分片技術:實現高效穩定的數據訪問(mongodbauto)
- 5如何在MongoDB中添加新用戶?(mongodb加用戶)
- 6Mongodb異步: 改善數據讀寫效率的有效方法(mongodb異步)
- 7提高數據管理效率,選擇MongoDB中國(mongodb中國)
- 8MongoDB在數據庫領域的占有率如何?(mongodb用的多嗎)
- 9使用MongoDB通配符進行精確查詢(mongodb通配符)
- 10使用MongoDB和JSP構建高效的Web應用(mongodbjsp)
- 11MongoDB連接配置:輕松入門!(mongodb 連接配置)
- 12從0到1實現mongodb增量更新操作(mongodbinc)

網友評論